Concepts in Latent Representations
Exploring how word vectors in a latent space represent concepts and their relationships
Project Overview
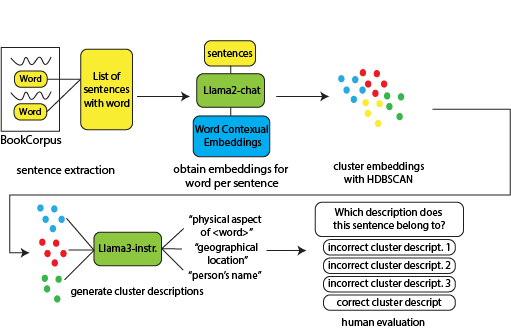
This ongoing project explores whether contemporary language models can identify and extract different context-dependent aspects of concepts from their embeddings, using polysemous words and clustering sentences containing those words. The results show that language models can encode and describe context-specific conceptual aspects, while also demonstrating an ability to understand and evaluate conceptual cohesiveness in sentence clusters.
Abstract
Concepts form the mental representations of words, and are used for high-level thinking, reasoning, and decision making, representing a core difference between humans and contemporary large language models (LLMs), which are trained at the token-level. While work has been conducted to evaluate LLMs’ conceptual understanding and to endow them with conceptual awareness, this work has mainly worked on prompting models, and not their latent embedding spaces. Yet, concepts have been encoded in embeddings for years: early embedding methods such as word2vec encoded certain conceptual relationships (ex: hypernym-hyponym), as apparent in the parallelogram rule. Therefore, I explore whether a contemporary model can identify and extract differ ent aspects of in-context, concepts from their embeddings. To do that, I take very polysemous words, which contain high contextual diversity and therefore aspects, cluster different sentences containing each word, and used an LLM to describe embeddings. Results show that the LLM can encode context-dependent aspects of concepts in its embeddings, can determine the highlighted aspect of a word in context, and can understand if a cluster of sentences is conceptually cohesive. This analysis suggests that LLMs can generate accurate descriptions of their concep tual aspects in context, and present an evaluation method to verify their correctness and another method to prove a model’s understanding of cohesive clusters. I also confirm that there is no simple metric to identify noisy and incohesive clusters, but do find a direct correlation between the number of clusters for a word and their frequency.
Progress
This project was presented as part of my CS 224N (Natural Language Processing with Deep Learning) class, advised by Stanford NLP postdoc Chen Shani. I demonstrate our preliminary results in this paper.
Future Directions
In the coming months, I plan to work with Chen and her advisor Dan Jurafsky to develop the paper towards a formal publication, while also refining some of the methods, using a larger corpus, and potentially changing the model used from Llama2 to Llama3.1.